Synthetic Data and Lidar Point Cloud Segmentation
The Long Road to Autonomous Driving
Autonomous driving (AD) has been the topic of research for multiple decades now, but only fairly recently have advancements in technology transformed this idea from sci-fi into a goal that seems achievable in the very near future. And that is a conservative statement, since autonomous driving has already been solved and implemented either in certain restricted domains or as partially autonomous solutions – or rather advanced driver assistance systems (ADAS). But a general-purpose solution, a personal self-driving vehicle capable of safe transportation from arbitrary point A to arbitrary point B is yet to become a reality.
So, what is holding us back? The general answer would be: time, money, research, and accident liability. With recent developments in sensor technologies including imaging radars, lidars, IMUs, and ASIC data processing, there is no doubt that current generation hardware is up to the task, but the software is not quite there yet. Machine learning and, more specifically, deep learning models involved in perception tasks are still being heavily researched. Not to imply that they are primitive by any stretch of the imagination, but rather that the problem they are trying to solve is highly complex.
Roads and traffic rules are pretty regular and straightforward, but the things found on those roads – cars, trucks, bikes, pedestrians, and other road traffic participants can be imprecise, unpredictable, and inconsistent. Naturally, the question of safety is raised, and the requirement for an extremely rigorous safety standard is imposed on the software.
The First of Its Kind
We have come a long way since the first steps towards AD were taken way back in 1989. A research project called ALVINN (An Autonomous Vehicle in a Neural Network) was conducted at the University of Pittsburgh, which pushed the limits of 80s technology by implementing a small neural network designed for road following. The “autonomous” vehicle used for research was called NAVLAB, and it was a modified small van with a video camera, a laser range finder, and 3 Sun Microsystems computers onboard with a 5kW energy consumption footprint. Despite the obvious hardware limitations, the project was fairly successful in achieving its modest goal. The neural network was tested in the NAVLAB vehicle on empty roads with no other traffic, under sunny conditions, moving at 0.5 meters per second, and it dictated a correct turn curvature approximately 90% of the time. Comparable results were achieved with the contemporary classical image processing approach.

NAVLAB equipped with a video camera, range finder, and 3 Sun computers
Historical intrigue aside, there is one particularly difficult problem that troubled the ALVINN team we can relate to even today, and their solution to this problem could be the correct next step for AD and ADAS development going forward.
Machine learning is data-hungry. The more – the better, both in terms of quantity and quality. Unfortunately for ML researchers in the 80s, there were neither. This was a problem for the ALVINN team, as it would be too difficult to get enough real data for sufficiently training their network. Not only that, but any changes in parameters such as camera orientation would require collecting an entirely new set of road images.
Instead, the ALVINN team turned to synthetic data generation. They developed a simulated road generator that creates road images along with corresponding simulated range finder images. Since the real images were fairly low-resolution anyway, it was extremely difficult to distinguish between real and simulated roads. Also, the model was trained exclusively on simulated images, which makes this accomplishment even more impressive.

Real and simulated road images
As we will see later on, there exist many modern implementations of the exact same idea – using simulated data to successfully increase the performance of modern road segmentation algorithms. But now, let’s talk a bit about sensors.
Rich Sensor Data
The growing reliance on data-hungry ML models is closely linked to the recent advancements in sensor technology. After all, a data-driven solution can only work with rich and quality sensor data. Digital sensors have come a long way since the days of ALVINN. High-resolution cameras provide a much better base for perception systems than what was previously available, and their ubiquity and mass production has driven their cost down. That is why modern ADAS systems can afford to employ multiple onboard cameras in varying orientations. And it is not just about cameras.
New sensor tech has opened the door to many new possibilities. Medium and short-range radars have also made an appearance in some automotive perception systems, having the obvious advantage of invariant operation in different weather and lighting conditions, along with implicitly deducing velocity using the Doppler shift. Imaging radars are also currently in the middle of exciting new developments and possible ADAS usages, and, while not the topic of this article, many of the observations made and solutions discussed here could easily be applied to imaging radars. Big leaps in camera and radar tech have enriched the datasets used for training with detailed information about the surroundings.
However, there is one sensor technology that can give us a high-resolution 3D scan of the surrounding environment. I am of course talking about lidar.
Lidar
Lidar (or light radar) is a novel sensor technology that has made its way into the automotive industry fairly recently. It consists of a laser that sweeps the surrounding area by emitting short light pulses and then deducing distance and object properties from the reflected beam. The result of this process are the exact coordinates of a point in space where the beam was reflected, and by repeating this many times per second in varying directions we get many coordinates for many points, aka a point cloud. The point cloud is a 3D representation of the sensor’s surroundings, with great detail and precision. This is something that even an array of cameras with depth perception can’t achieve easily. Modern lidar units like Velodyne Puck can give us a 360-degree view within a 100m range, with about 300,000 points per second. That is a lot of data.
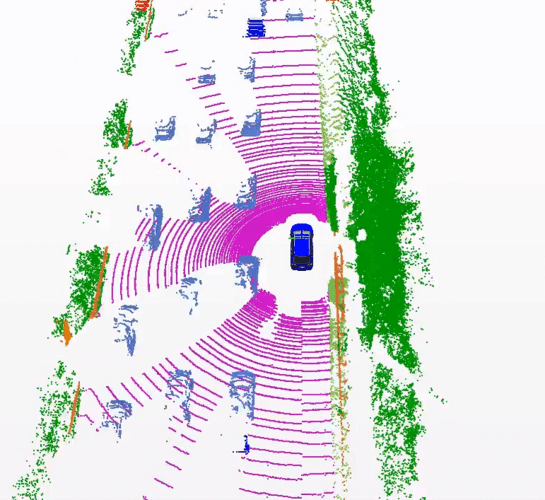
Lidar scan from the SemanticKITTI dataset
A single camera has no depth perception, and radar sensors, even though more versatile since they work in all weather conditions, typically are lower in resolution compared to lidar. It seems obvious that having a 3D scan of its surroundings would be incredibly useful to an autonomous vehicle for safely navigating through different environments. In fact, the introduction of lidar was a key advantage for the self-driving car Stanley, the first autonomous vehicle to successfully complete the DARPA Grand Challenge consisting of a harsh desert track that had to be navigated fully autonomously.
Sounds too good to be true, and it is, in a way. Lidar still has some problems to address before it will join other sensors in mainstream AD and ADAS systems. Lidar point clouds are very detailed and contain lots of data. More data may yield better results from an algorithm, but will also require more processing power. Also, lidar sensors are still very expensive. But as mentioned at the beginning of the article, the hardware might be expensive, but it is viable. On the other hand, camera deep learning models have decades of research behind them, while point cloud models don’t.
Point cloud deep learning models are an area under heavy research and development, and they share the same problems as the early ALVINN models, a lack of training data being one of the biggest. Annotating three-dimensional data like a point cloud is a difficult and tedious task. Even though there are companies that offer advanced tools and solutions to ease this task, there is still only a small amount of open and available lidar point cloud datasets for researchers, the most prominent being SemanticKITTI, Nuscenes, and Pandaset. Generating, labeling, and segmenting new point cloud datasets is expensive, and just like with ALVINN, models can be sensitive to changes in sensor configurations like relative sensor/camera position, etc. Instinctively, researchers thought of solving these problems the same way they did in the past – with synthetic data generation.
Synthetic Data
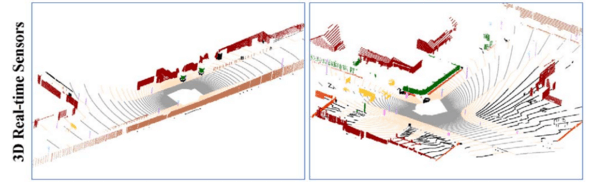
Synthetic data offers great potential for cost reduction when it comes to generating datasets. Gathering equipment, locking in a specific sensor configuration, driving around different environments in varying weather conditions for hundreds of hours, all of this could potentially be avoided by generating data virtually. Synthetic data can be generated and regenerated from a 3D world quickly and for different sensor configurations, weather conditions, traffic rules, etc. And even though the real world is a lot more “detailed” than a 3D simulation, the data we are after sees the world from the eyes of a lidar sensor. And there has been quite some research in trying to model a real-world lidar sensor for a virtual world. The images below represent a real-world scene scanned with a lidar, and a virtual replica of the same scene scanned with a virtual lidar model of the actual sensor. Can you tell which is which?

Lidar scan of a real-world scene, and a virtual replica
Virtual Worlds
There is no shortage of driving simulators featuring urban and rural areas, varying weather and lighting conditions, pedestrian traffic, autonomous vehicle traffic with cars, trucks, buses, bikes, and photorealistic graphics. Using video games for generating synthetic lidar data seems like the obvious solution to our problem. These are sophisticated simulations with high-polygon graphics, physics engines, and AI road traffic participants. All we have to do is pick a game, add a lidar sensor, and have it drive around generating data. Since the game already knows how to tell the difference between a road, car, truck, bike, tree, etc., the generated data will be automatically labeled and segmented for “free”.
Of course, someone had the exact same idea. A lidar emulator was built into the popular AAA game GTA V. This synthetic lidar was modeled after a real-world lidar with specific characteristics. The researchers constructed a pipeline called SqueezeSeg based on a convolutional neural network. The goal was to generate point-wise labels for cars, pedestrians, and cyclists. With this approach, it was possible to generate hundreds of hours of driving lidar point cloud data. When training SqueezeSeg with synthetic data only, relatively poor test accuracy of 29% was recorded when testing on real data. In a later paper, SqueezeSegV2 improved upon this by mitigating dropout noise, achieving better but still relatively poor 57% test accuracy.
Combining Synthetic and Real Data
From this, we have learned that training exclusively on synthetic data yields poor performance when moving to real data. Even if we pull data from modern, high-polygon video games, it’s still not “realistic” enough to be used exclusively as training data. So this approach might be too optimistic. One thing to consider would be synthetic data generation that would supplement real datasets in order to increase the accuracy of existing models.
Another research paper used the open-source simulator for autonomous driving: CARLA (Car Learning to Act). The end product was a small framework that works as a plugin for CARLA and can be used to automatically generate lidar point clouds with user-defined sensor configuration, thus solving the issue regarding model sensitivity to sensor configuration. The researchers constructed a virtual lidar sensor that uses ray casting to simulate a laser ray. Plugin users can set the configuration to generate synthetic data of different real-world sensors such as Velodyne HDL-64 (used in the KITTI dataset) or a high-resolution static laser scanner (used in the Semantic3d.net dataset).
Velodyne HDL-64 synthetic scan in CARLA simulator
This plugin was used to generate point-wise segmented lidar data for the purposes of pretraining a deep learning model for semantic point cloud segmentation, similar to SEGCloud developed by Lyne Tchapmi et al. in 2017. The model was then trained with 1/8 of the real-world KITTI training data and tested on the KITTI test set. The results were compared to the point-wise segmentation accuracy of the same model when trained with the KITTI training set only. The results showed a slight drop in point cloud segmentation accuracy.
Although the accuracy was reduced, this paper gave proof that it was possible to greatly reduce the amount of real sensor data for model training (12.5% of the original training set) and supplement it with synthetic sensor data from a low-polygon asset simulator like CARLA, with only a slight drop in segmentation accuracy. The CARLA plugin can be easily reused to generate data for another project and is available on GitHub. One could hypothesize that by adding new assets to the open-source simulator, like higher polygon vehicle and pedestrian models or city maps with a more detailed environment, achieving even higher segmentation accuracy when pretraining with such synthetic data would be entirely possible.
Such a hypothesis was confirmed with similar research done by X. Yue et al. where a framework for automatic extraction of point cloud data with ground truth labels can be done from the popular video game GTA V. This paper showed significantly better results, probably due to GTA V containing a much richer environment than what is available with CARLA assets. The framework can also do automatic calibration between collected point clouds and images which can then be used for sensor fusion tasks. Users can also interactively construct specified scenarios that can be used to systematically test, analyze, and improve lidar-based learning algorithms for AD.
The framework was used to generate point-wise segmented synthetic lidar data from a car driving autonomously in the video game world. Training the DL model on synthetic data alone yielded poor results when tested on the KITTI set. This is mostly because the distributions of the synthetic dataset and KITTI dataset are quite different. But when combining the generated synthetic data with the KITTI training set, the accuracy was almost 9% better on the KITTI test set compared to using only KITTI data.
A Hybrid Approach
As we have seen in previous results, it is entirely possible to increase lidar point cloud segmentation accuracy by supplementing the training process with generated synthetic data. However, there is a hybrid approach that has yielded very promising results.
Instead of generating completely synthetic data, a novel approach was considered. The problem with using synthetic data from virtual simulators is mostly that the environment lacks real-world detail, variation, and imperfections. The general idea was to use a high-resolution lidar sensor to create a detailed 3D scan of city roads. Afterward, this scan would be edited by removing all dynamic objects from the scene, such as road traffic participants, pedestrians, and other things capable of motion. The result would be a completely static point cloud map of the environment.
After this preprocessing is done, virtual vehicle and pedestrian models (or at least their point cloud representations) are reintroduced into the scene. The advantage of this approach might not be obvious at first glance. Why not just train our model with the recorded data, why bother removing real traffic participants and then reintroducing synthetic ones?
Vehicle models and their point cloud representations are almost identical to real vehicle scans. Having an empty static real-world map means we can reintroduce motionable objects in a virtually endless number of combinations and permutations, thus increasing training data size very easily. And this training data is of much higher quality than purely synthetic data generated from a video game like GTA V or CARLA, since the surrounding environment actually represents the real world. Having a high-resolution static scan means we can easily downsample to represent other commercial lidar sensors used in vehicle perception systems.
In this paper, a professional high-speed 3D scanner (Riegl VMX-1HA) was used as a mobile mapping system that provides dense, accurate, and feature-rich data at highway speeds. Scans that are this detailed can be later used to simulate other popular lidar scanners like the commonly used Velodyne HDL64E S3.
After removing motionable objects, a probability map for obstacle placement was made for object reintroduction. By using this probability map, it is possible to generate many different combinations of obstacle placements, each of these combinations being a completely valid point cloud for model training.
This hybrid approach has demonstrated very promising results in terms of point cloud segmentation accuracy. The whole pipeline is a complex system, but all things considered, it might well be the correct step towards the further development of autonomous driving vehicles.
Arijan Amigh, Development Engineer at NOVELIC
References
- [1] Dean A. Pomerlau, 1989. An autonomous land vehicle in a neural network, Dean A. Pomerleau, Computer Science Department Carnegie Mellon University
- [2] Dosovitsky et al., 2017. Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., Koltun, V., 2017. CARLA: An open urban driving simulator, in: Proceedings of the 1st Annual Conference on Robot Learning, pp. 1–16
- [3] D. Griffiths and J. Boehm, 2019. A Review on Deep Learning Techniques for 3D Sensed Data Classification, Remote Sensing, vol. 11, no. 12, p. 1499, Jan. 2019
- [4] Khaled Elmadawi et al. 2019. Khaled Elmadawi, Moemen Abdelrazek, Mohamed Elsobky, Hesham M. Eraqi, and Mohamed Zahran, End-to-end sensor modeling for LiDAR Point Cloud
- [5] A. Gaidon et al. 2016. A. Gaidon, Q. Wang, Y. Cabon, and E. Vig, “Virtual Worlds as Proxy for Multi-Object Tracking Analysis,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4340– 4349.
- [6] Mohammed Hossny et al., 2020. Mohammed Hossny, Khaled Saleh, Attia Mohammed, Ahmed Abobakr, Fast Synthetic LiDAR Rendering via Spherical UV Unwrapping of Equirectangular Z-Buffer Images
- [7] D. Griffiths and J. Boehm, 2019. David Griffiths, Jan Boehm, 2019. SynthCity: A large scale synthetic point cloud
- [8] Fei Wang et al., 2019. Fei Wang, Yan Zhuang, Hong Gu, Huosheng Hu, 2019. Automatic Generation of Synthetic LiDAR Point Clouds for 3-D Data Analysis
- [9] Ivan Stepanov, 2020. Synthetic lidar data generation using carmaker free space sensor plus
- [10] Beltrán J. et al., 2019. Beltrán, J., Cortés, I., Barrera, A., Urdiales, J., Guindel, C., García, F. & de la Escalera, A. (27-30 October, 2019). A method for synthetic LiDAR generation to create annotated datasets for autonomous vehicles perception [Proceedings]. 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, pp. 1091-1096.
- [11] X. Yue et al., 2018 X. Yue, B. Wu, S. A. Seshia, K. Keutzer, and A. L. Sangiovanni-Vincentelli. A lidar point cloud generator: from a virtual world to autonomous driving. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, pages 458–464. ACM, 2018. 1, 2, 3
- [12] Jin Fang et al., 2019. Jin Fang, Dingfu Zhou, Feilong Yan, Tongtong Zhao, Feihu Zhang, Yu Ma, and Liang Wang, Ruigang Yang, Augmented LiDAR Simulator for Autonomous Driving
- [13] Hassan Abu et al., 2017. Hassan Abu, Alhaija Siva, Karthik Mustikovela, Lars Mescheder, Andreas Geiger, Carsten Rother, Augmented Reality Meets Computer Vision: Efficient Data Generation for Urban Driving Scenes
- [14] Imitation Learning
- [15] RandLANet
- [16] Yuan Wang et al., 2018. Yuan Wang, Tianyue Shi, Peng Yun, Lei Tai, Ming Liu, 2019., PointSeg: Real-Time Semantic Segmentation Based on 3D LiDAR Point Cloud
- [17] Bichen Wu et al. 2018 Bichen Wu, Xuanyu Zhou, Sicheng Zhao, Xiangyu Yue, Kurt Keutzer, UC Berkeley 2018., SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud
- [18] L. Tchapmi et al. 2017. L. Tchapmi, C. Choy, I. Armeni, J. Gwak, and S. Savarese, “SEGCloud: Semantic segmentation of 3D point clouds,” in Proc. Int. Conf. 3D Vis., Qingdao, China, Oct. 2017, pp. 537–547.